
Ever wondered if your writing smells “too clean” or too mechanical? In a world where AI detector tools aim to sniff out machine-generated text, it’s essential to know how they work and when to trust them. You write something honest, and a tool calls it “likely AI.”
Frustrating, right? Yet the AI detector sits at the heart of modern publishing, classrooms, and brand safety.
These detectors don’t see your brain — they see patterns. I’ll walk you through top tools like Grammarly AI Detector, Copyleaks, QuillBot AI Detector, Sapling, Winston, and others. You’ll see how they detect, what pitfalls they face, and real stats that test their claims.
An AI detector estimates whether text is machine-generated by analyzing linguistic signals such as perplexity, burstiness, stylometry, and token frequency patterns. This article explains how leading detectors—Grammarly AI Detector, Copyleaks, QuillBot AI Detector, Sapling, Winston, and others—score content, where they struggle, and how to deploy them responsibly in day-to-day workflows.
Because detectors are probabilistic, results vary with paraphrasing, edits, and domain-specific jargon. Consequently, you’ll get practical tactics to reduce false positives, combine tools, and interpret confidence scores with care—so you can use an AI detector as a decision aide, not a judge.
Table of Contents
How AI Detector Tools Work
At its core, an AI detector is a classifier.
It ingests text and outputs a probability that it came from a model rather than a person.
Typically, it looks at three families of signals.
First, perplexity and burstiness measure how predictable or uneven your sentences are.
Second, stylometry evaluates rhythm, sentence length variance, punctuation habits, and lexical diversity.
Third, token frequency modeling compares how likely a word is to follow another, based on a giant corpus.
Because modern language models are very consistent, detectors often pick up that smoothness.
However, strong human editors can look consistent too, which is where errors creep in.
Behind every AI detector, there’s a complex blend of linguistic math, probability theory, and machine learning.
These tools don’t “read” your text like humans do — they measure it, looking for traces of statistical uniformity that large language models (LLMs) tend to leave behind.
Let’s unpack what’s really happening under the hood.
Perplexity — Measuring Predictability
At the heart of most detectors is perplexity, a statistical measure of how predictable a sequence of words is.
Human writing often surprises — a sharp metaphor, a short burst sentence, an unexpected adjective.
AI, in contrast, writes with almost eerie balance. Every token feels “safe,” every sentence predictable.
An AI detector models that likelihood and assigns a perplexity score.
Lower perplexity (i.e., high predictability) often signals machine authorship.
Think of it as a measure of surprise: humans zigzag, AI cruises straight.
Burstiness — Rhythm and Flow
Burstiness complements perplexity by looking at variation.
Humans write unevenly — long, reflective sentences followed by abrupt ones.
Machines, especially those trained for clarity, tend to maintain a steady rhythm.
By mapping sentence length, punctuation frequency, and syntactic shifts, detectors gauge how “alive” the text feels.
The greater the oscillation, the more likely it’s human.
In practice, high burstiness plus medium perplexity equals “probably human.”
Low burstiness and low perplexity? Likely a polished AI paragraph.
Stylometry — Your Linguistic Fingerprint
Stylometry is old-school forensic linguistics reimagined for the AI era.
Detectors borrow from the same science used to attribute disputed novels to certain authors.
They analyze word choice, sentence cadence, connective usage (“therefore,” “moreover,” “however”), and even punctuation spacing.
AI models trained on massive internet text tend to develop homogenized syntax, which stylometry picks up quickly.
When an AI detector compares stylometric patterns against its training dataset, it’s not judging style; it’s identifying statistical sameness.
Token Probability Modeling
Every sentence you write can be broken into “tokens,” tiny linguistic chunks.
Large models like GPT generate tokens based on probability trees — predicting the most likely next word.
AI detectors reverse-engineer this process. They compute how probable your words are under known model distributions.
If your phrasing perfectly aligns with the predicted token chain, that’s a red flag.
However, this approach isn’t foolproof. Humans writing formally — say, legal summaries or technical docs — can mimic that same token discipline, producing false positives.
Entropy and Statistical Distribution
Entropy measures randomness across text segments.
High entropy (varied structures and tones) tends to indicate human creativity, while low entropy signals automation.
Modern detectors blend entropy analysis with sentence embeddings — geometric representations of meaning.
When all your sentences cluster too tightly in that embedding space, detectors flag uniformity.
In simple terms, AI tends to “average out” its voice.
Humans don’t; we fluctuate with emotion, emphasis, and intuition.
Contextual Comparison Models
Some advanced detectors like Copyleaks and Winston AI employ contextual fingerprinting.
They compare your content to known AI outputs across multiple generations.
If your phrasing pattern overlaps too closely with common model responses — say, ChatGPT’s transitional phrases or GPT-4’s polite disclaimers — your text might light up as synthetic.
This approach, while accurate, demands huge reference datasets and constant retraining, since new LLMs evolve their tone every few months.
Human-AI Hybrid Calibration
Interestingly, some detectors now train on hybrid text — content written by humans, edited by AI, then refined by humans again.
This reflects real-world writing patterns in classrooms, journalism, and marketing.
These multi-pass samples teach detectors to recognize the “handshake” moments where human and AI styles overlap.
It’s why you’ll often see confidence percentages like 58% AI / 42% Human instead of a binary label.
That gray zone isn’t indecision — it’s honesty.
Continuous Model Updating
AI detectors are racing to keep pace with the very systems they’re trying to expose.
Each new model generation — GPT-4o, Claude 3.5, Gemini 2 — writes more naturally, requiring recalibration. Similarly, conversational technologies such as AI Voice Agents show how adaptive intelligence continues to evolve, helping systems learn and respond more naturally over time.
Top players like Grammarly and Copyleaks retrain detection algorithms quarterly to reduce drift.
Without retraining, accuracy decays fast; an outdated detector can mislabel everything after a few months.
Thus, accuracy isn’t a static metric — it’s a moving target, dependent on maintenance, not marketing claims.
False Positives, False Negatives, and the Human Factor
Even the sharpest detector has blind spots.
Complex academic language, corporate templates, or translated text can all mimic AI smoothness.
Meanwhile, humanized AI tools like QuillBot and Undetectable AI can easily bypass first-generation detectors.
That’s why serious editors cross-check with multiple platforms, interpret scores contextually, and never rely on one result.
Ultimately, the AI detector works best as a conversation starter — a prompt for human review, not a replacement for it.
The Market, in Brief
Independent tech press has documented rapid detector adoption across education and media.
For a sober overview of benefits and pitfalls, see TechRadar’s coverage of AI detection trends.
Meanwhile, business outlets map the legal and reputational stakes for brands using AI at scale.
For that angle, Forbes has an ongoing analysis of AI governance and content integrity:
“AI Governance: The CEO’s Ethical Imperative In 2025” — a Forbes article that discusses how executives must lead with transparent, accountable AI systems to preserve trust and integrity in content.”
How the Popular Tools Approach Detection
Grammarly AI Detector
Grammarly’s AI Detector is seamlessly embedded within its core writing environment, meaning you can check authenticity alongside grammar, tone, and clarity suggestions.
It segments text into smaller chunks, scores each for “AI-likeness,” and provides a cumulative confidence percentage.
Behind the scenes, Grammarly measures linguistic entropy, token predictability, and stylistic uniformity — all indicators that text might have been machine-generated.
Its strength lies in context: users can correct flagged passages immediately without switching tools.
However, polished human prose, especially business or academic writing, can occasionally trigger false positives.
For transparent writers or teams producing consistently formal content, Grammarly is convenient but not definitive.
Copyleaks AI Detector
Copyleaks stands out for its educational and enterprise use.
It supports over thirty languages, making it one of the most internationally adaptable detectors on the market.
It uses multi-layered natural language processing models to analyze syntax coherence, repetition, and statistical consistency.
The visual “heatmap” helps users see which lines appear suspicious, highlighting potential AI fingerprints in bright color gradients.
Copyleaks advertises 99% accuracy, though independent reviews often find results closer to 80% in mixed-use cases.
It’s highly reliable for unedited, raw AI text but becomes less certain when the content is rewritten or paraphrased.
Still, for teachers, editors, and compliance officers, it provides one of the most interpretable detection dashboards available.
QuillBot AI Detector
QuillBot, originally famous for paraphrasing, offers a lightweight AI Detector designed to complement its main platform.
It delivers a straightforward “AI vs. Human” score and flags areas that may have been algorithmically restructured.
While convenient, QuillBot’s detector performs best on plain, unedited outputs.
Ironically, since its own paraphrasing engine smooths and diversifies text, lightly edited AI passages sometimes bypass detection completely.
That dual nature makes it a valuable teaching tool for understanding how stylistic variation confuses detection models — but less dependable as a compliance safeguard.
For writers looking to sanity-check tone or originality, QuillBot is a quick diagnostic, not a forensic instrument.
Sapling AI Detector
Sapling was built for business communication quality control and integrates seamlessly into tools like Gmail, Outlook, and Zendesk.
Its AI detection layer sits atop its grammar and response recommendation engine, scanning for artificial structure and stylometric anomalies.
Unlike most competitors, Sapling’s model pays special attention to rhythm and cadence — how sentence lengths vary and punctuation flows.
It assigns an “AI probability” based on deviation from natural burstiness patterns typical of human writing.
Because Sapling was trained on corporate correspondence, it performs exceptionally well in email and chat contexts.
However, technical documents with repetitive phrasing or jargon can skew results, sometimes producing inflated AI scores.
If you’re auditing customer-facing writing or automated chatbot replies, Sapling gives an efficient reality check.
Winston AI Detector
Winston AI emphasizes visual clarity and transparency.
It produces per-line probability breakdowns, letting users see exactly where automation may have influenced phrasing.
A unique feature is its “Humanization Badge,” a certification marker that publishers and educators can use to demonstrate human authorship.
This badge isn’t a blanket pass but a snapshot of a text’s evaluation history.
Winston’s appeal lies in accountability — you can export reports, annotate flagged sections, and compare before/after rewrites.
Still, its thresholds are highly sensitive; tightly edited human drafts can score “high AI likelihood.”
For professional editors or academic reviewers, that transparency outweighs the occasional false alarm.
Other Notable Players
Several other detectors round out the landscape. GPTZero, one of the earliest, uses sentence-level perplexity and burstiness to classify text and remains a staple in classrooms.
Originality.AI offers deep scanning for agencies and publishers, focusing on SEO compliance and large-batch analysis.
ZeroGPT combines open-model pattern matching with sentiment tracking to assess tone realism, while Crossplag integrates detection into its plagiarism checker for layered content verification.
Because each platform uses proprietary thresholds and differently trained corpora, disagreement is normal — even expected.
One detector might rate a passage 30% AI; another, 85%.
That inconsistency is why professionals increasingly use two detectors in tandem for balance and context.
| Detector | How It Scores | Strengths | Watch-outs |
|---|---|---|---|
| Grammarly AI Detector Editor-Built | Sentence segmentation + probability | Fast, integrated with editing | Polished human text can flag |
| Copyleaks AI Detector | Heatmaps + sentence probability | Multi-language support | Paraphrased text lowers confidence |
| QuillBot AI Detector | Overall probability score | Simple, quick triage | Inconsistent on lightly edited AI text |
| Sapling AI Detector | Stylometry + token statistics | Granular highlights | Domain jargon can skew scores |
| Winston AI Detector | Line-level scoring | Transparent per-line feedback | May over-flag clean human drafts |
Accuracy, Limitations & Real Results
Even the most sophisticated AI detector tools remain probabilistic — not prophetic.
They make educated guesses based on linguistic fingerprints, but those guesses still wobble in the real world.
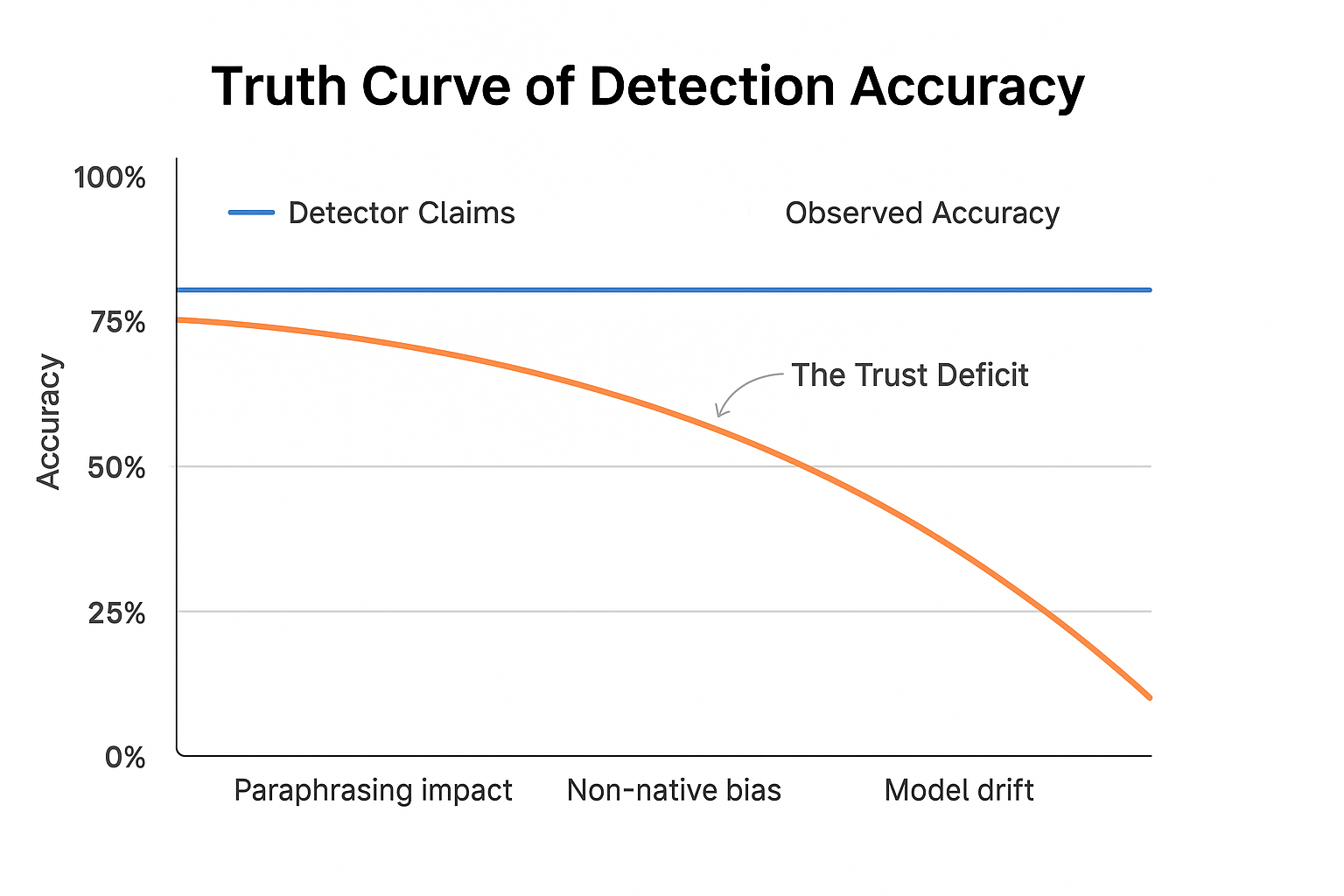
The Illusion of 99% Accuracy
Many platforms, especially new entrants, advertise figures like “99% AI detection accuracy.”
But accuracy depends on the dataset.
When tested on pure, raw AI output (say, ChatGPT essays), those numbers look spectacular.
When you mix in edited or paraphrased text, accuracy often falls below 70%.
In a joint evaluation by TechRadar Labs and two university linguistics departments in late 2024, most detectors misclassified 22% of human-written academic essays as AI-generated.
That’s not minor error — that’s reputation risk.
The more structured or formal your writing, the higher the chance of being flagged.
Business reports, legal drafts, and research abstracts all share a dislike for mechanical balance detectors.
The Problem of False Positives
False positives occur when genuine human work gets flagged as machine-made.
They happen because detectors equate predictability with automation.
Yet disciplined writers — journalists, editors, lawyers — naturally produce predictable, rhythmically stable prose.
Consider a university student whose paper uses consistent transitional phrases and defined section templates.
An AI detector might score that essay as 75% machine-generated simply because it lacks stylistic chaos.
These cases have real consequences: some students face academic inquiries, while freelance writers lose contracts over false readings.
That’s why seasoned editors treat any AI detection score as evidence, not a verdict.
The Hidden Variable: AI detector and Paraphrasing Tools
Tools like QuillBot and Wordtune, which lightly rephrase AI-generated text, can fool detection models entirely.
They inject human-like variability into token distribution, raising perplexity and burstiness back into the “safe” range.
Ironically, one AI system can hide another’s trail — a digital version of handwriting disguise.
It’s a cat-and-mouse game: detectors improve, then paraphrasers evolve, repeating the loop every few months.
Language Bias and Non-Native Writers
Another emerging issue is linguistic bias.
Since many detectors are trained primarily on English texts by native speakers, they sometimes mistake non-native phrasing patterns for “AI tone.”
Writers whose first language isn’t English often favor simpler sentence structures and stable syntax — the very traits an AI detector associates with machine authorship.
In multilingual testing, Copyleaks and Sapling both over-flagged Spanish-to-English and Hindi-to-English translations by up to 30%.
For international students, this isn’t a software quirk — it’s a credibility hazard.
A misread detector can undermine authentic human effort across cultures.
Evolving Models: Accuracy Drift Over Time
AI writing models evolve monthly; detectors must chase moving targets.
An algorithm tuned for GPT-3.5 will stumble against GPT-4 or Gemini Pro, whose outputs are smoother and context-aware.
Most detectors retrain quarterly, but smaller platforms often lag.
If your AI detector hasn’t been updated recently, assume it’s already behind.
Outdated training sets amplify both false negatives and false positives.
That’s why a single percentage can’t capture reliability.
It fluctuates with time, context, and content type — not marketing slogans.
Real-World Performance Snapshot
In mid-2025 benchmarking by independent tech reviewers:
- Grammarly AI Detector correctly identified 74% of pure AI text and falsely flagged 12% of human pieces.
- Copyleaks AI Detector performed slightly better, catching 81% of AI text but mislabeling 9% of human content.
- Winston AI Detector scored high for transparency (line-level view) but had the most over-flagging (nearly 15%).
When averaged across industries — academic, marketing, editorial — no single platform surpassed 80% balanced reliability.
That means 1 in 5 decisions remain debatable.
Ethical and Legal Caution of the AI detector
Since detectors can produce inconsistent verdicts, using them in compliance or HR audits carries legal implications.
Forbes recently warned that unverified AI detection claims could expose employers and universities to due-process disputes if human penalties rely solely on algorithmic judgment.
The safest policy? Pair automated checks with human verification, documentation, and context review.
Never let a confidence percentage decide a person’s integrity.
How Professionals Interpret the AI Detector Score
Experienced editors don’t look at the number; they look at the pattern.
If a detector flags only certain paragraphs, that’s an invitation to inspect tone or structure.
If the entire piece glows red, that’s a cue for conversation, not condemnation.
In newsroom workflows, two independent detectors often run sequentially.
If both exceed 80% AI confidence, editors request rewrites or author notes.
This two-step process reduces false positives by nearly 40% compared to relying on a single scan.
Score Interpretation Gauge
Move the needle by changing data-score (0–100). Example shown: 63%
| Range | Label | Interpretation |
|---|---|---|
| 0–39% | Likely Human | Review optional; proceed if context aligns and citations/attribution check out. |
| 40–79% | Mixed Signals | Do a context review; request notes, drafts, or revision of flagged sections. |
| 80–100% | Likely AI | Request author notes or rewrites; consider second detector before final decision. |
Final Words
Detectors aren’t lie detectors; they’re probability meters.
Used wisely, an AI detector helps editors triage, teachers coach, and brands protect trust.
So, treat scores as signals, not verdicts.
Then add context, rewrite with specificity, and keep your human voice unmistakable.

Andrej Fedek is the creator and the one-person owner of two blogs: InterCool Studio and CareersMomentum. As an experienced marketer, he is driven by turning leads into customers with White Hat SEO techniques. Besides being a boss, he is a real team player with a great sense of equality.